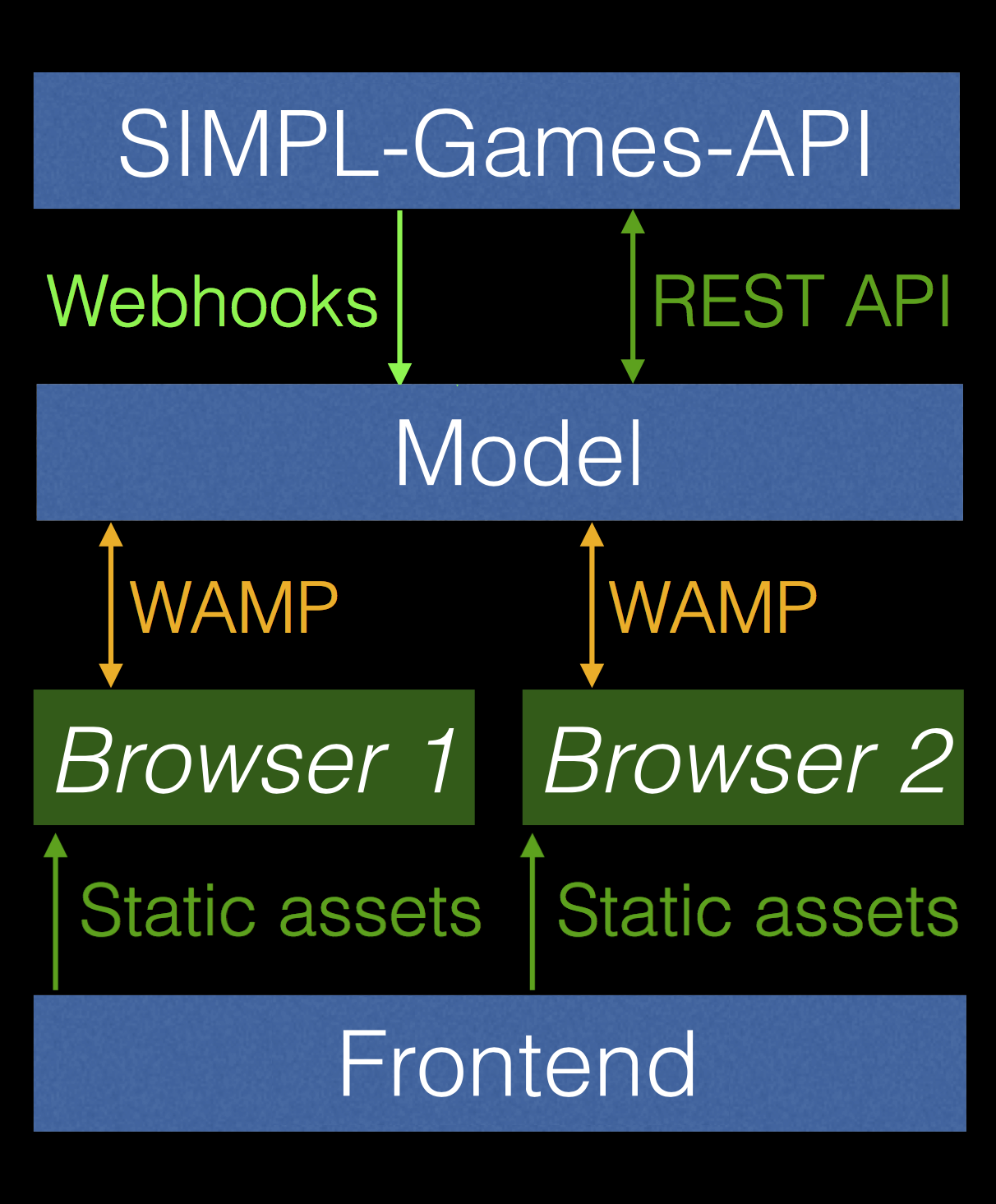
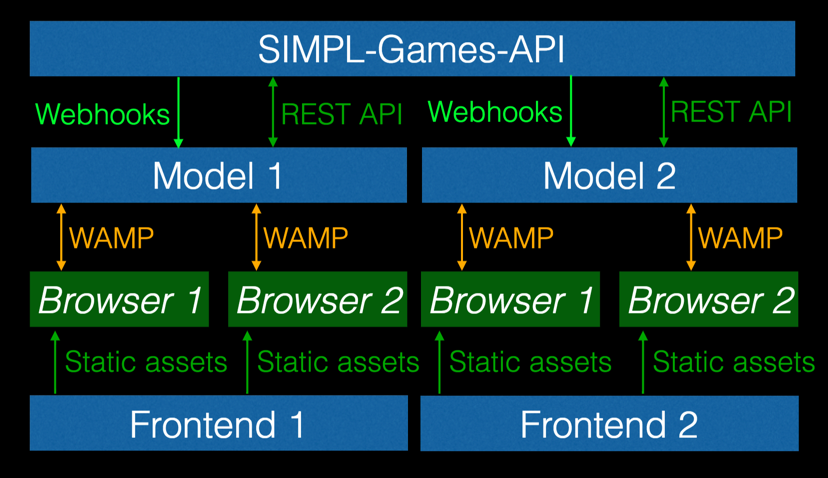
Code starts at the model-level. So before we wrote one line of SIMPL (the Learning Lab’s new simulation framework), we needed to figure out what, exactly, our data model would look like. Considering the ambitious goal of the project — a simulation framework that could support all of our current games as well as games yet unknown — we had to be very careful to create one that would be flexible enough to adjust to our growing needs, but not so complex as to make development overly challenging. Luckily, we have decades worth of simulation development expertise on our team, and were able to draw from that wellspring of knowledge when we worked on SIMPL’s foundational data model.
Code starts at the model-level. So before we wrote one line of SIMPL (the Learning Lab’s new simulation framework), we needed to figure out what, exactly, our data model would look like. Considering the ambitious goal of the project — a simulation framework that could support all of our current games as well as games yet unknown — we had to be very careful to create one that would be flexible enough to adjust to our growing needs, but not so complex as to make development overly challenging. Luckily, we have decades worth of simulation development expertise on our team, and were able to draw from that wellspring of knowledge when we worked on SIMPL’s foundational data model.
A data model, I should say, is basically the definition of how data is stored in the system, and how the pieces of data relate to one another. When we began the process of creating SIMPL, we needed to define the logical pieces that create a simulation, and build relationships among those pieces that, well, made sense.
Speaking the Same Language
Our first challenge was agreeing upon a nomenclature for the pieces that comprise a simulation in general. This may seem like a fairly trivial process; after all, everyone pretty much knows what we mean when we say a “game run,” or a “decision,” or a “scenario.” However, the implications of this language when developing a data model meant different things to different people — especially when we tried to communicate these requirements to the outside vendor working with us on the platform. With that in mind, we ended up creating a glossary of terms, defined right in the context of the simulation platform. This glossary helped us bridge the gap between our team and the vendor, allowing us to talk about terms in ways we all agreed upon and understood.
Start with What You Know
Once we agreed on the definitions of various parts that make up a sim, we began to map out what our data model would look like. To assist us in this process, we leaned on our collective years of simulation experience here in the Learning Lab — namely, the games we’ve already supported and developed. Then came the whiteboarding (sooo much white boarding), wherein we drew relationships between objects and assessed if the connections we were making made sense.
 The results of one of our white-boarding sessions.
The results of one of our white-boarding sessions.
We then broke down existing games and made sure the new data model would be able to accommodate the unique implementation of each of those sims. This served as a valuable “smoke test” for us — i.e., a way to ensure we were on the right track. To that end, we picked games with diverse implementations in order to be 100-percent certain the model we were creating was flexible enough to meet our needs.
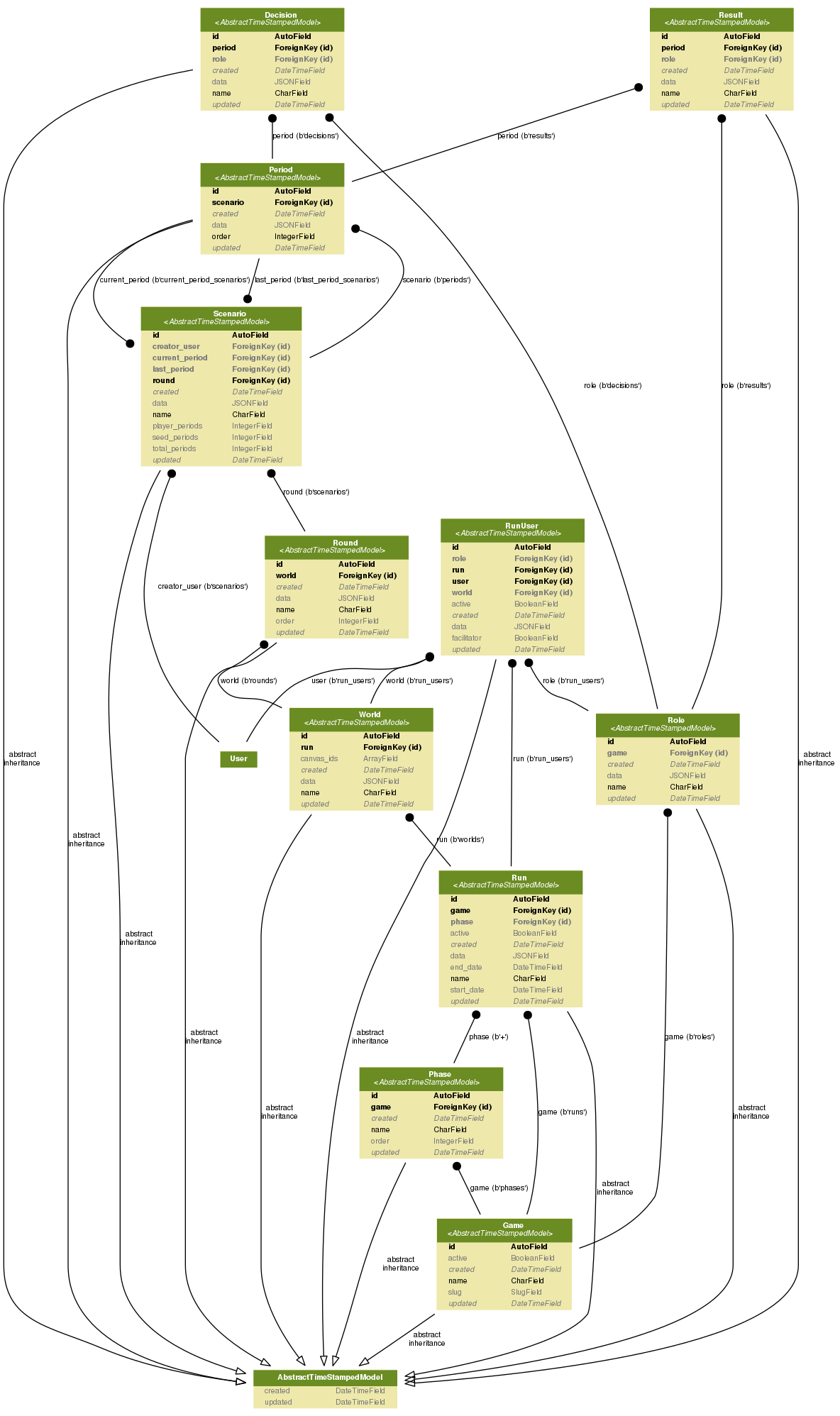 The current SIMPL data model.
The current SIMPL data model.
Where to Go from Here?
After a long period of iteration, we finally settled on a data model that made sense to both us and our vendor. We made further changes along the way as development progressed, but the main structure we came up with remained the same from whiteboard etchings to the implementation of our first sim. Going forward, of course, every new simulation we develop will be an opportunity to test the limits of this model, which we can improve or simplify where and when the need arises.
Moreover, the lessons we learned building our data model for SIMPL could be applied to any data-driven application. In that regard, here are the main things we came away with:
- Take time to think deeply about your data model, and do so in collaboration with project managers and developers who will ultimately be responsible for the application. The decisions you make here will dramatically impact the future of your application. It’s easy to make changes when you’re working on a whiteboard; it’s a lot harder to do so once you’ve written applications dependent on the model.
- Don’t assume everyone knows what you mean when describing the model. And, perhaps equally important, empower your team members to speak up when something does not make sense. Data models can be complex animals, and the more everyone understands, the better end result you will have.
- Test your assumptions. Before a single line of code is written, walk through hypothetical applications with your data model. Can you get the data you need in a duly sensible way? Do the relationships you’ve built reflect the logic required within the application? The more tests you run, the more confidence you have in making sure you have a solid model.
In the wise words of George Harrison, “If you don’t know where you are going, any road will take you there.”
That same logic can be applied to creating a data model that hits all the right notes. Given that this critical construct would be the cornerstone of our new simulation framework, if we hadn’t spent the time to exhaustively map out all of our needs (as well as how SIMPL would meet them), then there was a good chance we would have lost direction and the whole project could have veered off course. So take it from us — while it can be tempting to take shortcuts when embarking on a project of this scale, carefully inching your way through a proper planning phase goes a long way toward ensuring that you’re ultimately able to reach your destination and meet your end-goals.